BigQuery cost control: del ahorro reactivo al gobierno preventivo
¿Qué es?
El lunes por la mañana, un líder técnico en una aseguradora de Bogotá abre el panel de facturación de Google Cloud y encuentra un salto del 40% en los costos de BigQuery. Nadie reportó fallas, no hubo ataques de seguridad y el equipo de analítica operó como de costumbre. El problema no fue un error técnico, sino una "consulta de exploración" lanzada por un practicante que hizo un barrido completo sobre una tabla histórica de diez años, sin particiones ni filtros.
Cuando el control de costos se limita a revisar la factura al final del mes, la organización está pagando un impuesto por desorden arquitectónico que BigQuery, por su naturaleza elástica, escala de forma silenciosa.
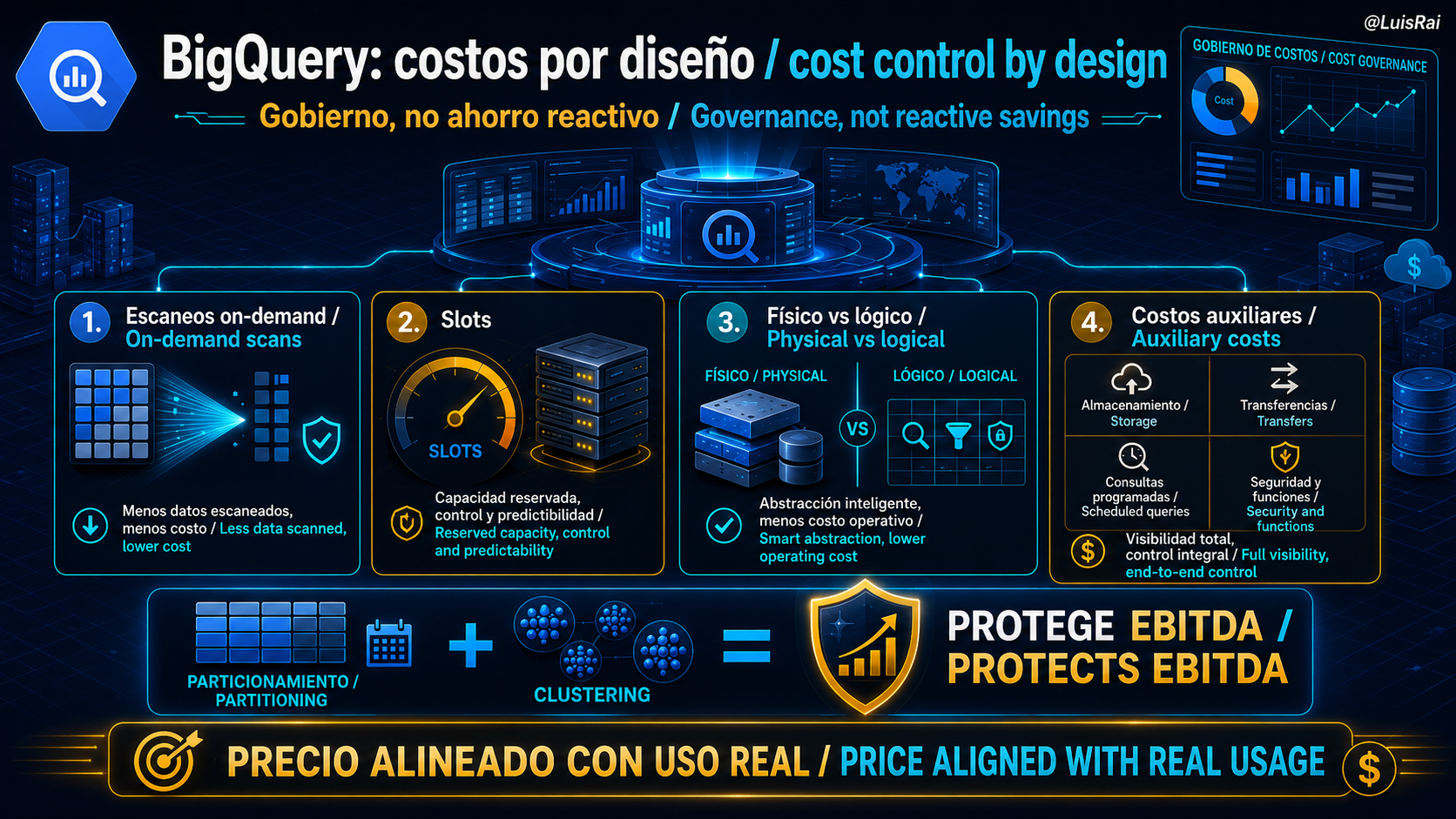
En términos simples, BigQuery separa el almacenamiento del procesamiento y factura este último por volumen de datos escaneados o por capacidad reservada. Un gobierno de costos real exige entender que la eficiencia no nace de prohibir consultas, sino de modelar los datos para que el motor lea lo mínimo necesario. Esto implica pasar de una mentalidad de "uso ilimitado" a una de "presupuesto por diseño", donde cada tabla y cada consulta se evalúan por su impacto financiero antes de tocar producción.
¿Qué aporta?
Jordan Tigani, ingeniero fundador de BigQuery, explica en su análisis sobre el fin del "Big Data" que la mayoría de las organizaciones no operan realmente a escala de petabytes, pero pagan la ineficiencia de sistemas diseñados para ello. Optimizar el costo aporta previsibilidad financiera, reduce la deuda técnica acumulada en modelos de datos ineficientes y libera presupuesto para experimentación real. En la práctica, un tablero que carga en tres segundos y cuesta diez centavos aporta más valor que uno que tarda un minuto y consume diez dólares por cada actualización.
La profundidad técnica exige entender que BigQuery no es un monolito de facturación. No basta con optimizar el escaneo bajo demanda; un gobierno serio contempla tres frentes concurrentes. Primero, la elección entre cómputo bajo demanda (pago por TB) y ediciones (Standard, Enterprise, Enterprise Plus) basadas en capacidad reservada o autoescalada (slots). Segundo, el modelo de facturación de almacenamiento: el tradicional lógico (datos sin comprimir) frente al físico (datos comprimidos), donde este último cobra por "viaje en el tiempo" (time travel) y ventanas de seguridad, siendo rentable solo en conjuntos de datos masivos y estables. Tercero, los costos auxiliares como la ingestión por streaming o el uso de funciones de IA, que pueden duplicar la factura si no se asocian a un compromiso de capacidad.
La diferencia entre una operación con base técnica y una sin ella se resume en cómo se aprovechan las jerarquías de almacenamiento y procesamiento. Una tabla sin optimizar obliga al motor a realizar un escaneo completo (full scan), mientras que una tabla gobernada utiliza particionamiento por tiempo y agrupamiento (clustering) por dimensiones de consulta para descartar bloques de datos irrelevantes, recortando el costo de ejecución en órdenes de magnitud.
¿Cómo implementar?
Un contraste operativo ayuda a fijar la diferencia entre una consulta ingenua y una optimizada por costo y rendimiento, considerando además el modelo de capacidad.
-- Escenario A: Consulta ingenua en modelo bajo demanda (Expensive and inefficient)
-- Full scan of a 2TB table without partition filters.
SELECT *
FROM `proyecto.dataset.ventas_historicas`
WHERE pais = 'Colombia';
-- Escenario B: Criterio técnico en modelo de capacidad (Slot optimization)
-- Using partition, projection, and pre-materials to reduce compute load.
SELECT fecha, id_producto, valor_neto
FROM `proyecto.dataset.ventas_gobernadas`
WHERE fecha >= '2026-06-01' -- Pruning: only scans blocks for this day
AND pais = 'Colombia' -- Clustering: skips non-matching blocks
AND sucursal = 'Bogotá'; -- IO reduction and slot savings
En el Escenario A, pagas por cada byte de la tabla o consumes miles de slots innecesarios. En el Escenario B, el particionamiento y el clustering reducen el costo bajo demanda hasta en un 90% y permiten que una reserva de slots atienda tres veces más consultas simultáneas.
Una rutina práctica para equipos reales debe evolucionar según el volumen. Para flujos de menos de 100TB/mes, priorice el modelo bajo demanda con cuotas personalizadas (QueryUsagePerUserPerDay) y alertas de facturación por proyecto. Para flujos masivos o con alta concurrencia, migre a una Edición Enterprise con reservas de autoescalado, fijando un límite máximo de slots para contener el gasto. En almacenamiento, realice el cambio a facturación física solo si su tasa de compresión supera el 50% y sus datos permanecen sin cambios más de 90 días (almacenamiento a largo plazo), de lo contrario, el costo del time travel anulará el ahorro. Finalmente, integre el validador de consultas (dry run) en los procesos de CI/CD para rechazar cualquier despliegue que proyecte un consumo desproporcionado.
¿Cómo impacta al ROI y al EBITDA?
Cuando el gobierno de BigQuery reduce el desperdicio operativo, el impacto se traslada directamente al EBITDA al convertir un gasto variable impredecible en un costo controlado y eficiente. En términos de ROI, cada peso ahorrado en escaneos innecesarios es capital que puede reinvertirse en mejorar la calidad del dato o en modelos de IA generativa que generen ingresos.
El valor humano decisivo en este marco no es solo saber escribir SQL, sino decidir fronteras de responsabilidad sobre el gasto. Esa combinación de criterio de arquitectura, lectura de factura y disciplina operativa separa a las empresas que ven la nube como un costo incontrolable de aquellas que la usan como una plataforma de crecimiento rentable.
Referencias y lecturas relacionadas
- Google Cloud BigQuery Cost Optimization Best Practices, documentación oficial: https://cloud.google.com/bigquery/docs/best-practices-costs
- Big Data is Dead de Jordan Tigani, análisis de industria: https://motherduck.com/blog/big-data-is-dead/
- BigQuery Editions documentation, guía técnica: https://cloud.google.com/bigquery/docs/editions-intro
- Monitoring BigQuery storage with INFORMATION_SCHEMA: https://cloud.google.com/bigquery/docs/information-schema-table-storage
- Google Cloud Pricing Calculator: https://cloud.google.com/products/calculator
Version in English
BigQuery cost control, from reactive savings to preventive governance
What is it?
On Monday morning, a technical lead at an insurance company in Bogotá opens the Google Cloud billing dashboard and finds a 40% jump in BigQuery costs. No system failures were reported, no security breaches occurred, and the analytics team operated as usual. The issue was not a technical bug but an "exploratory query" launched by an intern that performed a full scan on a ten-year historical table, without partitions or filters.
When cost control is limited to checking the bill at the end of the month, the organization is paying a tax for architectural disorder that BigQuery, by its elastic nature, scales silently.
In simple terms, BigQuery separates storage from processing and bills the latter by volume of data scanned or by reserved capacity. Real cost governance requires understanding that efficiency is not born from banning queries, but from modeling data so the engine reads the minimum necessary. This means moving from an "unlimited use" mindset to a "budget by design" one, where every table and every query is evaluated for its financial impact before touching production.
What does it add?
Jordan Tigani, founding engineer of BigQuery, explains in his analysis on the end of "Big Data" that most organizations do not actually operate at petabyte scale, but they pay the inefficiency of systems designed for it. Optimizing cost provides financial predictability, reduces technical debt accumulated in inefficient data models, and frees up budget for real experimentation. In practice, a dashboard that loads in three seconds and costs ten cents adds more value than one that takes a minute and consumes ten dollars per refresh.
Technical depth requires understanding that BigQuery is not a billing monolith. It is not enough to optimize on-demand scanning; serious governance contemplates three concurrent fronts. First, the choice between on-demand compute (pay-per-TB) and editions (Standard, Enterprise, Enterprise Plus) based on reserved or autoscaled capacity (slots). Second, the storage billing model: traditional logical (uncompressed data) versus physical (compressed data), where the latter charges for time travel and fail-safe windows, making it profitable only for massive and stable datasets. Third, auxiliary costs such as streaming ingestion or the use of AI functions, which can double the bill if not associated with a capacity commitment.
The difference between a technically grounded operation and one without it comes down to how storage and processing hierarchies are leveraged. An unoptimized table forces the engine to perform a full scan, while a governed table uses time partitioning and clustering by query dimensions to discard irrelevant data blocks, cutting execution costs by orders of magnitude.
How to implement?
An operational contrast helps fix the difference between a naive query and one optimized for cost and performance, also considering the capacity model.
-- Scenario A: Naive query in on-demand model (Expensive and inefficient)
-- Full scan of a 2TB table without partition filters.
SELECT *
FROM `project.dataset.historical_sales`
WHERE country = 'Colombia';
-- Scenario B: Technical criteria in capacity model (Slot optimization)
-- Using partition, projection, and pre-materials to reduce compute load.
SELECT date, product_id, net_value
FROM `project.dataset.governed_sales`
WHERE date >= '2026-06-01' -- Pruning: only scans blocks for this day
AND country = 'Colombia' -- Clustering: skips non-matching blocks
AND branch = 'Bogotá'; -- IO reduction and slot savings
In Scenario A, you pay for every byte in the table or consume thousands of unnecessary slots. In Scenario B, partitioning and clustering reduce on-demand costs by up to 90% and allow a slot reservation to serve three times as many concurrent queries.
A practical routine for real teams must evolve according to volume. For flows under 100TB/month, prioritize the on-demand model with custom quotas (QueryUsagePerUserPerDay) and per-project billing alerts. For massive flows or high concurrency, migrate to an Enterprise Edition with autoscaling reservations, setting a maximum slot limit to contain spending. In storage, switch to physical billing only if your compression ratio exceeds 50% and your data remains unchanged for more than 90 days (long-term storage); otherwise, time travel costs will cancel out the savings. Finally, integrate the query validator (dry run) into CI/CD processes to reject any deployment that projects disproportionate consumption.
How does it impact ROI and EBITDA?
When BigQuery governance reduces operational waste, the impact moves directly to EBITDA by converting unpredictable variable spending into a controlled and efficient cost. In terms of ROI, every peso saved on unnecessary scans is capital that can be reinvested in improving data quality or in generative AI models that generate revenue.
The decisive human value in this framework is not just knowing how to write SQL, but deciding responsibility boundaries over spending. That blend of architecture judgment, billing analysis, and operational discipline separates companies that see the cloud as an uncontrollable cost from those that use it as a platform for profitable growth.
References and Related Readings
- Google Cloud BigQuery Cost Optimization Best Practices, official documentation: https://cloud.google.com/bigquery/docs/best-practices-costs
- Big Data is Dead by Jordan Tigani, industry analysis: https://motherduck.com/blog/big-data-is-dead/
- BigQuery Editions documentation, technical guide: https://cloud.google.com/bigquery/docs/editions-intro
- Monitoring BigQuery storage with INFORMATION_SCHEMA: https://cloud.google.com/bigquery/docs/information-schema-table-storage
- Google Cloud Pricing Calculator: https://cloud.google.com/products/calculator